The British Convict Transportation Registers is a database detailing the journeys of over 123,000 people transported to Australia in the 18th and 19th centuries. Compiled from British Home Office records, it contains information such as the name of each person being transported, the date they departed, and their final destination.
The early stages of the Digital Panopticon have allowed us to perform some preliminary data linkage between these registers and people sentenced to transportation in the Old Bailey Proceedings. We’ve made the links primarily by name, with a degree of tolerance for spelling. We found that many names actually matched exactly, suggesting that perhaps names were in some cases directly copied from one record to another. A further 7% of names could be matched via an algorithm known as Soundex, which attempts to identify names which sound similar when spoken, but might be (accidentally) spelt differently. A remaining handful were matched by virtue of having a small Levenshtein Distance. Levenshtein is a simple metric by which the variance between two text strings is quantified. Including matches with a very small Levenshtein Distance, where perhaps only a single letter is different or omitted, helps take account of minor clerical errors.

Results of attempted name matching between the British Transportation Records and Old Bailey Proceedings.
In total, about 70% of the people sentenced to transportation in the Proceedings appear in the transportation records. We can be quite confident of about half of these, because in some cases the date of conviction is actually given in the transportation record. If the date and name match, it becomes very likely that we’re dealing with the same individual. For transportation records where a conviction date is not given, we have to examine five or six years worth of Old Bailey records to make sure we don’t miss a possible match. This greatly increases the possibility of a false positive, so we can be less sure about these links.
One interesting trend is that the number of exact links decreases significantly in cases where the conviction date is not given. A greater proportion of these links had to be made with Soundex or Levenshtein Distance. This suggests that the links made without a conviction date are less reliable, as we might expect. Therefore, for the time being we will discard these.
With our most reliable links in hand, we can begin looking for patterns between the details of conviction and transportation. One of the most interesting pieces of information contained in the transportation records is the destination of convict ships. An obvious question is whether convicts were directed to particular destinations based upon their offence, gender or age. One might imagine colonies having a need for people with particular skills or attributes at particular times, and the system might have attempted to address these needs. Luckily, occupation is indeed sporadically recorded in the Old Bailey Proceedings.
In fact, the data shows that the overwhelming factor in deciding where a convict was sent was the particular year when they left England. Transportation was almost exclusively to New South Wales before 1831, and overwhelmingly to Van Diemens Land after 1838. There is a brief period from 1832 to 1835 where roughly equal numbers of convicts are sent to both destinations. However, even during that period, there doesn’t appear to be any correlation between the characteristics of a convict and their destination. Neither gender or age, crime or occupation seem to have made any difference. Once a person was in the transportation system, their final destination was entirely arbitrary. There was no easily identifiable tendency to send people with particular attributes to particular destinations.

Sankey diagram, showing proportions of different age groups transported to different destinations between 1832 and 1835, including where the destination is unknown because a link between records could not be made.
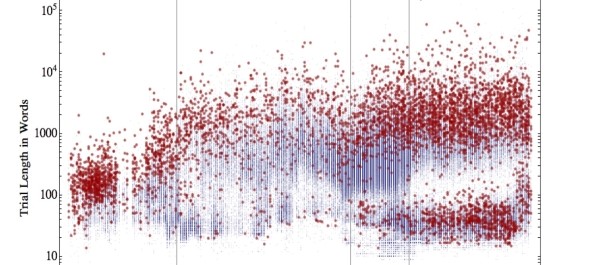
If we cannot find a pattern in where people were sent, perhaps we can find a pattern in how long it took them to be sent there. For every convict there is a period of time between when they were convicted and when they actually set sail aboard a ship. The interval between conviction and transportation is hugely variable. A few people were transported in little over a month. Some people, as we have noted, spent six years waiting to be transported.

Line graph showing the minimum, maximum and average intervals between conviction and transportation between 1787 and 1852.
The data shows that again, time was a very important factor. Transportation almost halted between 1835 and 1844, as did sentences of transportation. In contrast, the system seems to have been at peak efficiency between about 1814 and 1834, but even then there are a few outliers (represented by the green line) who still had to wait a very long time to be transported.

Detail of a scatterplot variation showing every interval between Proceedings conviction and BTR transporation, represented by horizontal bars running from conviction date to transportation date. Females are blue, males are orange.
If we look at the data in more detail, we can see that a great many of those sentenced to transportation, at least early in the period, are simply waiting for the next boat to depart. Convicts sentenced at multiple sessions are stored up until, presumably, there are enough to justify a voyage. Nevertheless, there are people who seem to miss multiple voyages; people convicted at the same session as those who depart on the next boat who are, for whatever reason, left behind. Can we detect any common characteristics among these people?
It is not at all easy to find a pattern, but there may be one: Male prisoners below the age of 15 appear to be kept for longer, on average, than those who are older. It’s worth noting that the minimum and maximum intervals show no such trend; there are still people under fifteen who are transported very quickly, and people over fifteen who are held for a very long time. But in terms of the average, there is a definite increase which starts abruptly at the age of fifteen and then accelerates as prisoners get younger. In fact, on average, male prisoners under fifteen are kept for twice as long as those over fifteen.

Age plotted against minimum, maximum and average days between conviction and transportation, for males sentenced at the Old Bailey 1787-1852.
This is a finding which we can begin to investigate and verify. Certainly, the pattern is not repeated for female prisoners, whose average transportation time remains remarkably consistent regardless of age. As the project gathers more data and continues its initial investigations, we hope to be able to explore this possible trend in more detail.
This is the very first linking exercise we have done, and there is undoubtedly scope to refine the process. Every dataset we add will help us to evaluate our findings more thoroughly and ask more detailed questions. The next step may be to try and link the Old Bailey and Transportation Registers to the Convict Database, which contains information such as height, and prisoner health. These may well be important factors in determining the treatment of prisoners and providing further clues as to the nature of a journey through the eighteenth century criminal justice system.